ESP32-C3实现属于你的AI语音助手:从语音识别到本地大模型对话-python版
1. 简介
最近各种“小智AI”设备火出圈,但大多数方案都基于 ESP32-S3,成本高,而且大多使用 C++ 编写驱动,开发门槛高。集成度越高的“小智AI”,越像一个黑盒,想改点功能都不容易。
而我手里的是一块价格亲民的 ESP32-C3,它虽然性能稍弱于 S3,但足够用来做基础的语音采集与控制;更重要的是,我喜欢用 Python 开发——幸运的是,MicroPython 让我可以在资源有限的嵌入式设备上继续享受 Python 的简洁与高效。
同时,家里有一台 GeForce RTX 4070 显卡电脑,正好可以本地部署 ASR(语音识别)、LLM(大语言模型)和 TTS(文本转语音)等全套模型服务。这样一来,整个 AI 对话系统都可以运行在本地,不仅响应更快,还完全由我掌控!
本文将带你一步步搭建一个“轻量级小智AI”系统,实现从语音输入、模型理解到语音输出的完整闭环,并实现一个自己的 MCP Server后端,真正打造一个属于你自己的 AI 助手生态。
2. 准备工作
2.1 购买ESP32-C3开发板套件
- ESP32-C3简约板(¥7.5)
- INMP441 I2S语音输入麦克风模块(¥11.3)
- MAX98357 I2S音频放大器模块(¥3.8)
- 3W8Ω喇叭(¥3.6)
- 0.96寸(128x64)OLED显示屏(¥6.8)
- 若干公对公杜邦线(¥1)
- 一块面包板(¥2)
- 一条usb-type-c数据线(¥2)
2.2 接线
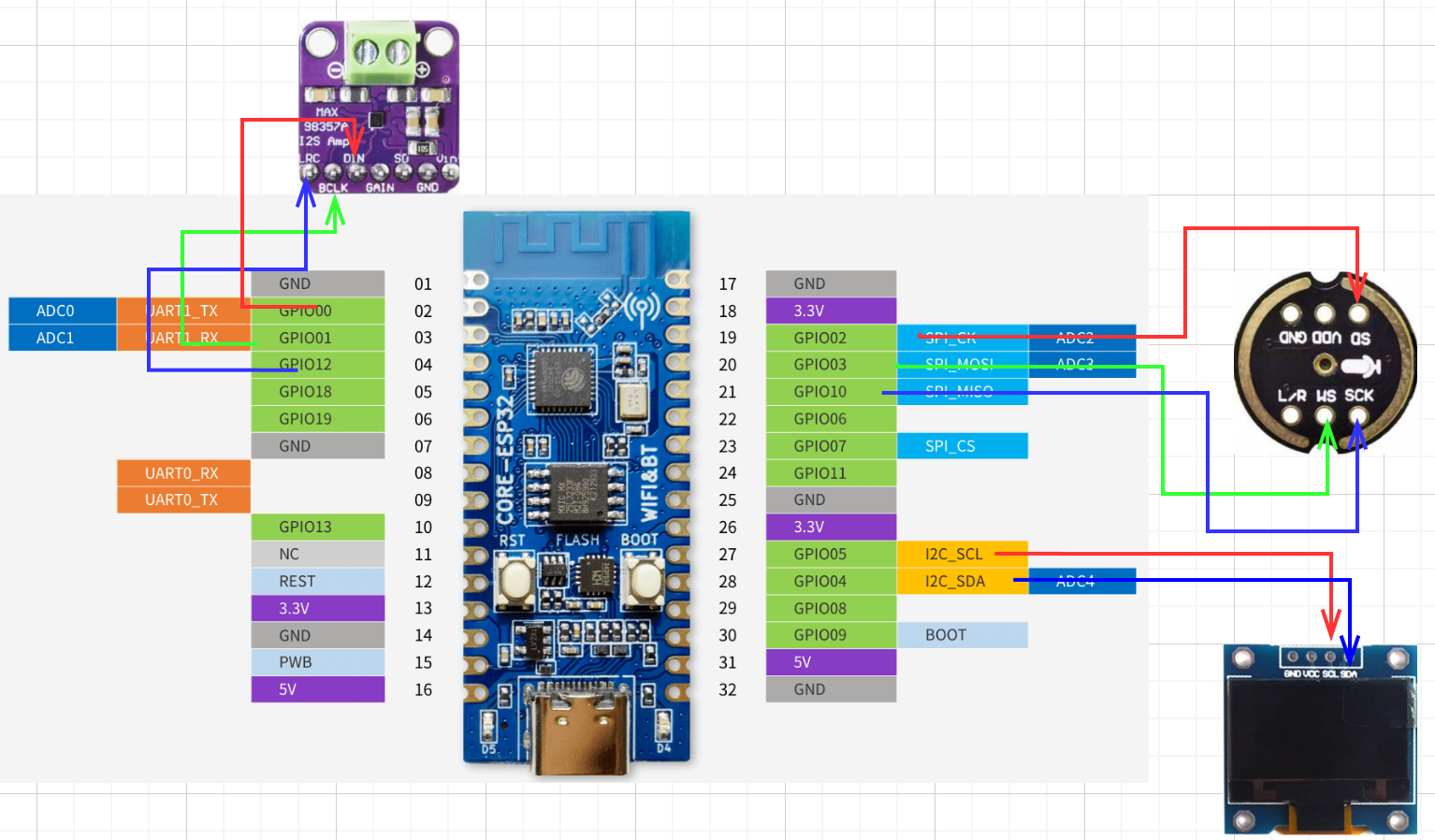
| ESP32-C3 | INMP441 | MAX98357 | OLED |
|---|---|---|---|
| VCC | VCC | VCC | VCC |
| GND | GND | GND | GND |
| GPIO00 | \ | DIN | \ |
| GPIO01 | \ | BCLK | \ |
| GPIO12 | \ | LRC | \ |
| GPIO02 | SD | \ | \ |
| GPIO03 | WS | \ | \ |
| GPIO10 | SCK | \ | \ |
| GPIO05 | \ | \ | SCL |
| GPIO04 | \ | \ | SDA |
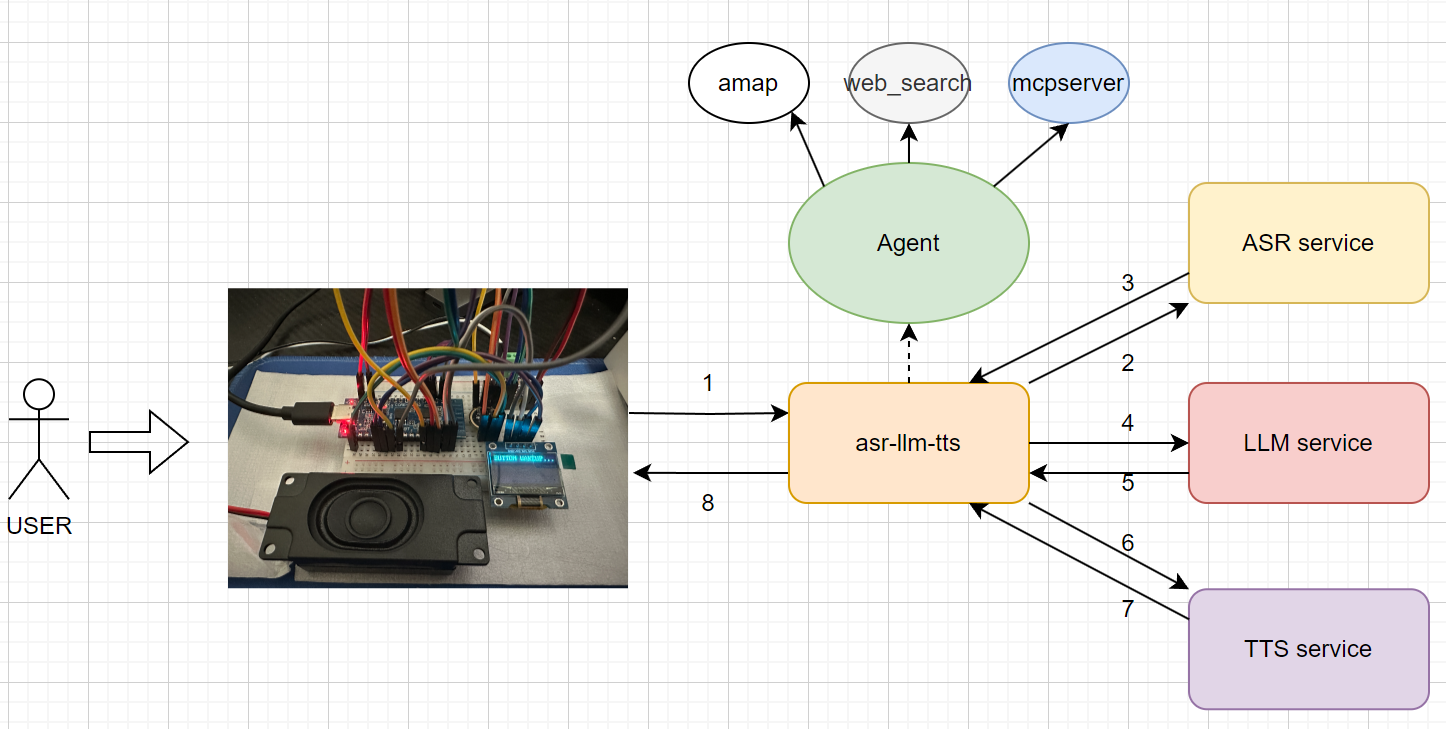
3. 整体解决方案
3.1 思路
- esp32c3开发板做IO端
- 音频输入:INMP441模块
- 音频输出:MAX98357模块
- 局域网ubuntu服务器做AI中枢
- 调用asr模块
- 输入esp32c3采集的pcm语音
- 输出识别的文字结果
- 调用llm模块
- 输入asr识别的文字结果
- 输出llm交互结果文字信息
- 调用tts模块
- 输入llm交互结果文字信息
- 输出文字转pcm音频结果,转发给esp32c3开发板通过MAX98357输出声音
- 支持本地和云端API两种调用方式
- 本地部署:本地部署asr-llm-tts套件,依赖局域网里有一台性能稍强的GPU服务器(如 GeForce RTX 4070的台式机)
- 优点:免费,隐私安全保障,个人数据保护,无需联网可离线运行
- 缺点:依赖asr-llm-tts套件所在服务器24小时开机提供服务;个人电脑提供的算力有限
- 云端API:调用阿里百炼的API(免费API根本用不完,嗨到爆)完成asr-llm-tts功能
- 优点:快速,可选择模型多,算力有保证
- 缺点:收费,隐私数据暴漏给API提供商,依赖网络
3.2 原理图
3.3 与其他同类产品对比优势
- 可本地离线部署,安全自主可控
- 全模块代码开源可高度定制
- 纯python实现,开发门槛极低
- 通过Qwen-Agent可轻松接入各种
function_tools,包括mcpserver - 易扩展。可作为智能家居中控,通过语音识别、语音播报,实现智能控制,轻松集成homeassistant
4. 环境部署
4.1 esp32-ai 烧录micropython固件到esp32c3
4.2 asr-llm-tts 本地AI中枢服务部署
- 准备一台ubuntu机器
- 根据仓库README.md配置运行环境
- 运行项目
4.3 asr 本地部署语音识别模块
- 安装部署
在GPU所在机器上部署和安装语音识别服务
- 踩坑记录
我选用了paraformer做语音识别,通过修改官方示例实现需求。奈何本人能力有限,未能参透demo里的magic 参数。通过不断的测试尝试最终得出:一次识别的pcm数据(bits=16, 频率=16000,单声道)大小为9600*2时的效果最好,不知道原因
1 | from funasr import AutoModel |
4.4 llm 本地部署llm
- 安装部署
在GPU所在机器上部署和安装llm服务。我采用无脑简单的ollama部署qwen3方案
- 踩坑记录
ollama 对 qwen3 的 enable_thinking 参数未适配好,当使用openai兼容api时,无法通过enable_thinking=False关闭思考模式,先临时通过在prompt前加/no_think前缀来关闭思考模式。
不知道是ollama问题还是Qwen-Agent问题,在streaming模式下,获取的输出并非delta_streaming,而是每个stream片段都包含前面已经输出的所有结果。这使得我在剥离delta generate text喂给tts模块的操作变得极其麻烦。
4.5 tts 本地部署语音合成模块
- 安装部署
在GPU所在机器上部署和安装语音合成服务
- 踩坑记录
在windows下部署,我发现将运行终端放到前台时速度很快,一旦窗口最小化,速度就变慢了,不知道具体原因,但我猜测和windows系统调度有关,我采用的workaround方案是使用windows shell cmd start /high方式启动来提高tts服务进程优先级,实测有用
1 | start /min /high "" python main.py |
5. 效果演示
- 开机后按下esp32c3开发板上的
BOOT按钮激活对话 - 只要不明确的与大模型“告别”(如再见,拜拜,退出等),就能一直保持对话交互
- 语音识别持续时间为
5s,一次会话结束到下次语音识别开始之间间隔0.5s
https://www.bilibili.com/video/BV1mTVfzfE5Y/
6. 总结
本文介绍了如何手工打造一款低成本,低门槛的AI语音助手。依靠python简洁高效的封装,让不懂嵌入式硬件开发的我也能轻松上手开发自己的AI语音助手。管他什么 I2S,I2C,中断,DMA,用micropython一把梭干就完事了!人生苦短,我用python!
